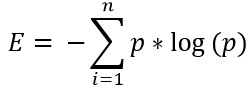What is greed and why is it there a negative connotation attached to it?
Wikipedia defines greed as: “Greed (or avarice) is an uncontrolled longing for increase in the acquisition or use: of material gain (be it food, money, land, or animate/inanimate possessions); or social value, such as status, or power. Greed has been identified as undesirable throughout known human history because it creates behavior-conflict between personal and social goals.”
But other terms – like ambition, savings, self preservation, achievement etc. – which are also associated with increase in personal worth, increase in status etc. are considered virtues. So longing for personal gain is in itself not bad, so it must be other traits that make greed a vice.
Following are the factors which make greed undesirable:
- Short Sightedness: Prioritizing instant gratification over long term gains.
- Negative Externalities: Greed not only hurt the your long term interests but also adversely affect others.
How Decision Trees work?
Decision Trees start select a root node based on a given condition and split the data into non overlapping subsets. Then the same process is repeated on the newly formed branches and the process continues till we reach desired result i.e. answer to our business question. The condition for splitting is the decided by the value of cost function. The condition corresponding to which the value of cost function, at that stage, is minimum is chosen. What I mean by at that stage is that overall value of cost function is not taken into account but the value of cost function at that level i.e. instant gratification. This approach may result in a tree for which overall value cost function may be higher than a tree in which splitting was done on the basis of overall value of cost function. Therefore this approach creates a tree whose accuracy is less that that of a tree where overall cost function was employed i.e. negative externalities. Therefore this approach is termed as greedy approach
Why is this approach chosen if it results in a suboptimal tree?
If the overall cost function was considered at every step, the process would have been highly computationally intensive. Thus by using greedy approach decision trees save both computation time and hardware costs.