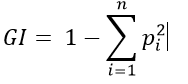Ensemble technique involves taking information from various sources before making a decision. We often employ it in our daily lives for ex: before buying a products we read several customer reviews, even our political system is based on ensemble method where choice(vote) of every elector is considered before choosing the candidate for the office.
Similarly when employing ensemble technique in machine learning, instead of using a single model, we use combine the output of several models to make the final prediction. How the outputs are combined depends on the type of ensemble technique employed.
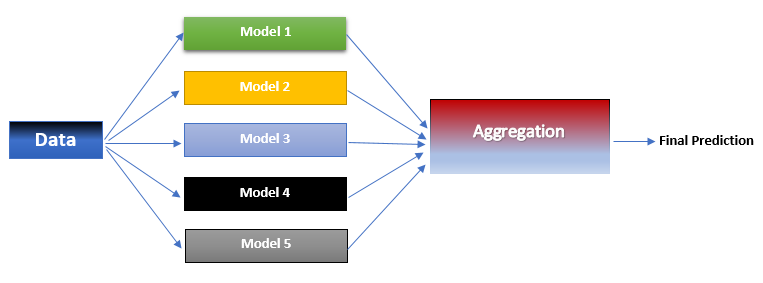
 Following are the advantages of using ensemble techniques:
Following are the advantages of using ensemble techniques:
- Model Selection: There are times when several algorithms are equally suitable to solve the problem and we’re not sure which one to chose. By employing ensemble learning we hedge our bets.
- Too Much or Too Little Data: If the dataset is large and has huge variance a single model won’t be able to identify and encapsulate all the patterns present in the data. By dividing it in subsets and using separate models suited to each subset we can arrive at much better results. On the other hand if the dataset is too small, ensemble techniques like bootstrapping that employ resampling can be of immense help.
- Complex Pattern: If the patterns present in the dataset are too complex to be modelled by a single equation, we can divide the dataset in a manner that each subset ends up with a simpler pattern. Then for each subset an appropriate algorithm can be used to model its pattern.
- Multiple Sources: In many real world scenarios we receive data from multiple sources that provide complimentary information. By using models for each source and combing their output we are able to get fuller view of the actual picture than by relying on model based on a single source.
- Increased Confidence: If multiple models make the same prediction, especially in classification problems, then we’re much more certain about the accuracy of that prediction.
Following are the types of ensemble techniques:
- Bagging
- Boosting
- Blending
- Stacking
- Blending