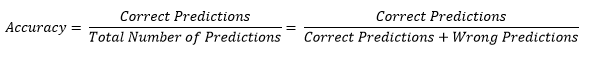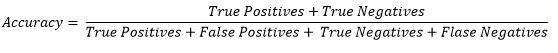Honorable Madras High Court said that-“1000 Culprits Can Escape but, One Innocent Should Not be Punished “. More or less legal systems around the world follow this principle.
The above motto shows that accuracy is not always the metric that is been sought out for. If you were to design a model that could assist the court in making decisions, then that model should also incorporate this dictum. The primary goal of your model would be to ensure that no innocent be predicted as guilty. Similarly there are many business scenarios where the end goal is not accuracy. For such cases we need metrics like precision & recall and confusion matrix forms the basis of calculating these metrics.
Further, in case of imbalanced datasets accuracy value can be sometimes misleading. Let me illustrate my point with an example, let’s say you have to build a model that has to predict if a person is Covid positive or not based on a given set of traits. If the training data is unbalanced with overwhelming number of healthy people and only a few Covid cases, then your model would incorporate this bias. If the the test data you use has 1000 rows in which there are 950 healthy(Covid negative) cases and 50 Covid positive cases. Now, if your model predicts 990 healthy cases (Covid negative) and 10 Covid positive cases, then your model horribly fails in its objective.

If out of 990 cases, that your model predicted negative, 940 are actually negative and of the 10 it predicted positive, 7 are actually Covid positive – then the accuracy of your model would be 94.7%. But this accuracy number is meaningless. What you need to know if of the corona positive cases, how many were actually predicted positive i.e. True Positive, and how many were wrongly predicted as corona positive i.e. False Positive. Similarly you would want to get the True Negative and False Negative values for the healthy cases.
In cases like this Confusion matrix based metrics like Recall and Precision come in handy.
Recall measures the number of True Positives out of the Total number of actual positive cases.
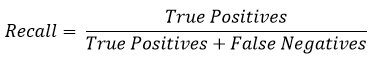
This metric is used in cases where you’re willing to compromise on accuracy of predicting negative cases but not on accuracy with which positive cases are predicted. In our Covid model example, recall is the metric that you would be most interested in. Even if the model predicts healthy people as Covid positive they physicians can rectify that error. But if Covid positive people are classified as healthy, they would leave the process at screening stage itself and thus:
- Would be deprived of the treatment
- Won’t be quarantined and could infect others
Precision measures the number of True Positives out of the Total number of positive cases predicted by the model.
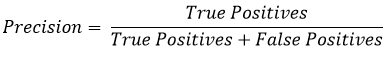
Precision is used to check the reliability of the model. If the precision of our Covid model were low, we wouldn’t rely too much on the results on the model and would:
- Build a new model with higher precision. This step would be used if the recall of the model is also low
- Include other checks in the screening process that further filter out the model results. This step would be taken if the model has high precision.
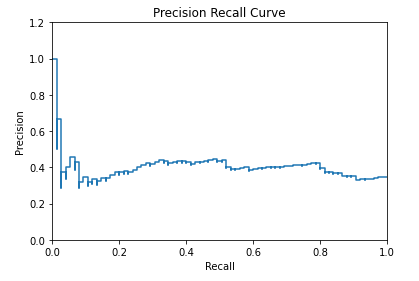
Thus recall is used to measure if the model is suited to the overall/business objective and precision is used to measure the reliability of the model results.